
Last-minute Cheat Sheet for AWS Certified Big Data Specialty
This is section two of How to Pass AWS Certified Big Data Specialty. In this post, I will share my last-minute cheat sheet before I heading into the exam. You may generate your last-minute cheat sheet based on the mistakes from your practices.
Cheat Sheet
Big Data Solution Design Patterns
- Big Data solution: the services for each stage
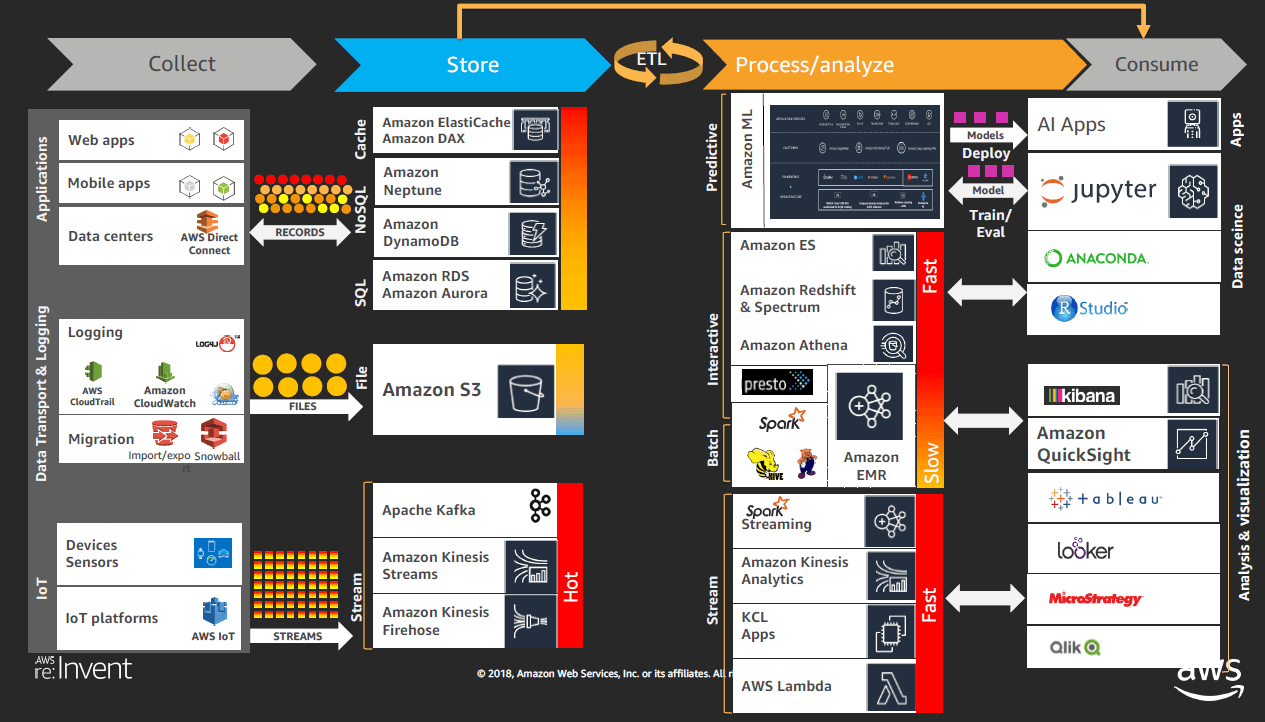
- Big Data design patterns on interactive and batch analytics
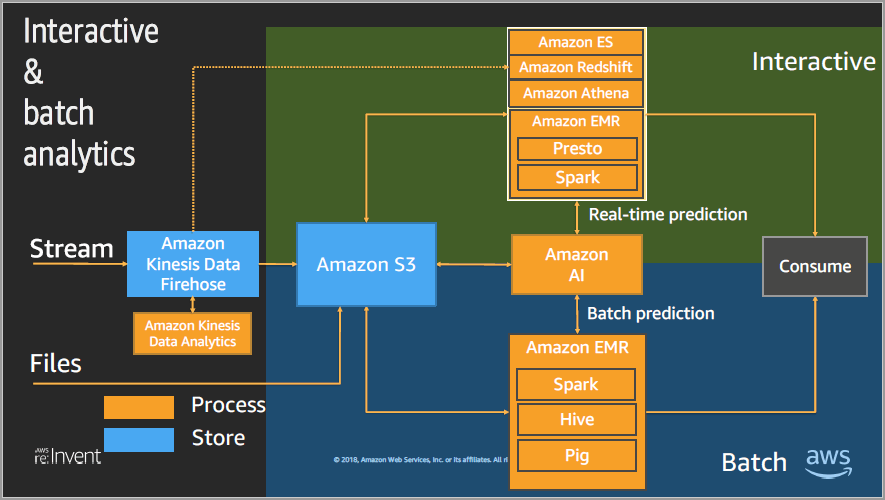
Services
- Kinesis Data Streams:
- Input – SDK, KPL, Kinesis Agent, Kafka, Spark
- Output – Spark, Kinesis Firehose, Lambda, KCL, SDK
- KPL can use either synchronous or asynchronous use cases. SDK can only support synchronous use cases. If use KPL for the producer then must use KCL for the consumer. Kinesis agent is for log monitoring java-based on Linux server with pre-processing data and rotation/checkpointing/retrying
- Enhanced fan-out pushes data to consumers with latency ~70ms
- VPC endpoint between VPC and KDS – no need of internet gateway, NAT, VPN or direct connect. Powered by Private Link for private communication between AWS services using an elastic network with private IPs in VPC
- Check whether KPL user records succeeded by using Future Object that is returned from addUserRecord
- KCL uses a DynamoDB table to keep track of the application’s state. Create the name of KDS application’s name of the table. Each application’s name must be unique
- Security: SSL endpoints HTTPS in flight, KMS, Own encryption libraries client-side, VPC endpoints with the private link, KCL needs to have read/write access to DynamoDB
- Kinesis Data Firehose:
- Input: Kinesis Data Streams, SDK, KPL, Kinesis Agent, CloudWatch logs/Events, IoT rules actions
- Output: S3, Redshift, ElasticSearch, Splunk
- Flush: buffer size or buffer time
- Data transformation: Lambda function e.g. from CSV to JSON
- Data conversion: JSON to Parquet/ORC
- Data compression: GZIP, ZIP, Snappy
- Security: attach IAM roles to S3/Redshift/ES/Splunk, encrypt delivery stream with KMS, VPC endpoint with the private link
- Kinesis Data Analytics:
- Input: KDS, KDF, reference data in S3
- Output: KDS, KDF, Lambda function
- Provision capacity: 1KPU= 1vCPU&4GB, default is 8KPU=32GB
- If the record arrives late to the application during the streaming process, then written to the error stream
- Monitoring: CloudWatch Alarms/Logs/Events, CloudTrail Log Monitoring
- Continues queries vs. Windowed queries (stagger, tumbling, sliding)
- Security: IAM role (read from KDS and reference data and write to the output destination)
- Collection
- Direct Connect: private, 1Gbps~10Gbps dedicated network connections. Direct connect gateway connects one or more VPC in different regions of the same account.
- Snowball: collect TBs or PBs data with KMS 256bit encryption. More than a week to transfer with SNS and text messages notification
- Data Migration Service: if the destination schema’s engine is different than the source one, then use AWS Schema Conversion Tool (SCT) to create DMS endpoints and tasks
- Lambda: timeout – 900 seconds, batch size – up to 10,000 records, split Lambda payload – limit 6mb, lambda process shard data synchronously and retry the batch until it succeeds or data expires
- SQS: 256kb per message sent
- Standard queue: horizontal scaling, at least once delivery
- FIFO queue: name of the queue with .fifo, sent exactly once, 5-mins interval de-duplication using duplication ID
- Security: client-side encryption must be implemented manually, VPC endpoint is provided through an interface, HTTPS, Server side KMS, IAM policy, SQS queue access policy
- S3:
- Knowledge on ETag, Versioning, Cross-Region Replication, CORS, lifecycle rules
- Security: SSE-S3, SSE-KMS, SSE-C, Client-side, SSL/Https, VPC endpoint via the gateway, Glacier (vault lock)
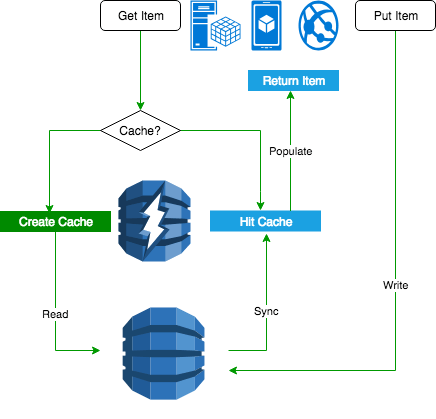
- DynamoDB:
- DAX

- GSI and LSI
- Partition=Ceiling(MAX(Capacity, Size)), Capacity = Total RCU/3000 + Total WCU/1000, Size = Total Size/10GB
- DynamoDB Streams: 24h data retention up to 1,000 rows/6MB
- Global table: same write capacity but not read capacity
- TTL: background job, attribute field (epoch time value), no affect read/write traffic
- Burst capacity: handles usage spikes. Adaptive capacity: continue reading/writing to hot partitions without being throttled
- Security: TLS/HTTPS, KMS, encryption cannot be disabled once enabled, IAM to access to tables/API/DAX, DynamoDB streams do not support encryption, VPC endpoint is provided through Gateway
- DAX
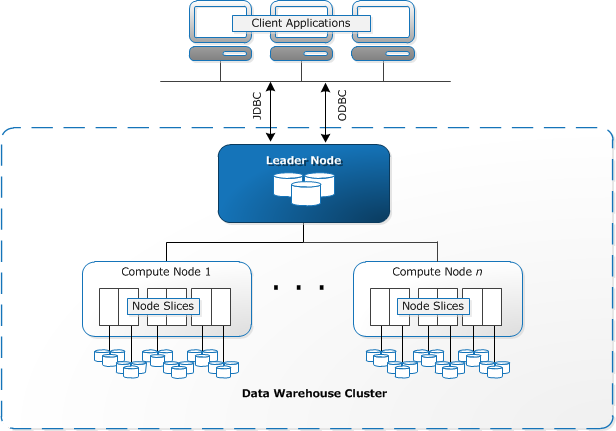
- Redshift
- Distribution styles: auto, even (round-robin), key (on one column), all (copied to every node)
- Leader node, compute nodes, MPP, Columnar data storage, column compression
- The optimal size of the file is 1MB to 125MB after compression
- Number of files = multiple numbers of slices in your cluster
- Break large files into smaller files (64mb)
- Copy and sync data between Redshift and PostgreSQL through DBLink
- Security: KMS or HSM (CloudHSM – Symmetric/asymmetric encryption, multi AZs), VPC (cluster security groups), SSE-S3, IAM roles access other AWS services, COPY/UNLOAD with access key and secret key
- Workload management: prioritize short/fast queries vs. long/slow queries
- EMR
- Apache Hadoop ecosystem cheat sheet
- Hive specific to EMR: load table partitions auto from S3, specify an off-instance metadata store, write data directly to S3, access resources located in S3
- The master node, core node (HDFS data + tasks), task node (only tasks)
- Enable CloudWatch metrics and SQS messages in EMRFS for S3 eventual consistency issue
- HDFS is useful for caching intermediate results during MapReduce processing or for workloads that have significant random I/O
- S3DistCP: copy data from S3 to HDFS or HDFS to S3
- Security: best practices for securing EMR
- Choose memory-optimized instance types (R4, R5, I3) for Spark
- Data Pipeline
- Input: S3, EMR/Hive, DynamoDB, RDS/JDBC
- Output: EC2, S3, EMR, RDS, DynamoDB, Redshift
- Define data node using DynamoDB as input for EMRActivity to launch EMRCluster
- Data Nodes: S3DataNode, DynamoDBDataNode, MySQLDataNode, RedshiftDataNode
- Databases: JdbcDatabase, RdsDatabase, RedshiftDatabase
- Activities: CopyActivity, HadoopActivity, EmrActivity , HiveActivity , HiveCopyActivity, PigActivity , RedshiftCopyActivity , ShellCommandActivity , SqlActivity
- Glue: Data Catalog, Glue Crawlers, and ETL (batch, not real-time)
- IAM policies for Glue service. Configure Glue to only access JDBC through SSL. Data Catalog: encrypted by KMS
- Athena
- Best practices: Partitioning (reduce the amount of data scanned), Compression and file size (splittable files to increase parallel reading) Columnar formats for analytics(Apache Parquet/ORC)
- Use Hive for DDL functionality – complex data types, the multitude of formats, and supports data partitioning
- QuickSight: SPICE
- Geospatial charts, KPI’s, scatter plot don’t support sort function
- Two permission policies:
| Rules for UserName, GroupName, Region, Segment | Result If You Grant Access | Result If You Deny Access |
|---|---|---|
| AlejandroRosalez,EMEA-Sales,EMEA,”Enterprise,SMB,Startup” | Sees all EMEA Enterprise, SMB, and Startup | Doesn’t see EMEA Enterprise, SMB, or Startup |
| [email protected],Corporate-Reporting,””,”” | Sees all rows | Sees no rows |
| User or group has no entry | Sees no rows | Sees all rows |
- ElasticSearch
- ElasticSearch vs. CloudSearch
- ELK (ElasticSearch, Logstash, Kibana)
- Access Kibana
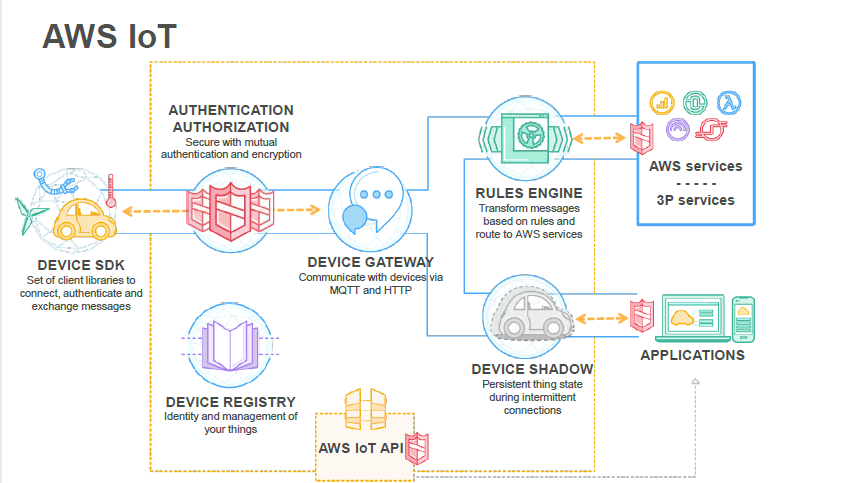
- IoT
- IoT Core
- Greengrass – bring compute layer to the device directly, execute Lambda functions on devices, and deploy functions from the cloud directly to devices
- IoT Core
- ML
- AI services: Comprehend – NLP, Lex – NLU&ASR, Polly – text to voice, Rekognition – identify objects/people/text/scenes/activities from image or video
- Sagemaker: fully managed ML service to build/train/deploy
- P2, P3 and G3 instance types for deep learning
Lesson Learned
- I am glad that I have the solid knowledge of Identity Providers and Federation before the test. I practiced the workflows/diagrams on Using Amazon Cognito for Mobile Apps, SAML 2.0, Enable SAML 2.0 to access AWS console before the exam.
- You should master at least three domains before you heading the exam. My solid knowledge of the domains storage, processing, analysis, and visualization especially on Redshift, DynamoDB, RDS, and ML helped me pass the exam.
- I didn’t do very good at Kinesis when choosing the best input among SDK, KPL, Agent or Kafka.
- I had a tough question on security in EMR. So read the document thoroughly especially Kerberos Authentication.
- You should arrive at the test center 30 minutes before the exam to have enough time to do the paperwork. Go to the bathroom before the exam.
- I did take a five-minute break to go to the bathroom in the exam. So if you need to take a bathroom break or eat an energy bar during the exam, just plan it before the exam.
- I didn’t see any question related to table operation, data types or commands on Redshift/DynamoDB/RDS in the exam.



